* Simplify bbox access
* Code cleanup
* Simplify bbox access
* Move code to face helper
* Swap and paste back without insightface
* Swap and paste back without insightface
* Remove semaphore where possible
* Improve paste back performance
* Cosmetic changes
* Move the predictor to ONNX to avoid tensorflow, Use video ranges for prediction
* Make CI happy
* Move template and size to the options
* Fix different color on box
* Uniform model handling for predictor
* Uniform frame handling for predictor
* Pass kps direct to warp_face
* Fix urllib
* Analyse based on matches
* Analyse based on rate
* Fix CI
* ROCM and OpenVINO mapping for torch backends
* Fix the paste back speed
* Fix import
* Replace retinaface with yunet (#168)
* Remove insightface dependency
* Fix urllib
* Some fixes
* Analyse based on matches
* Analyse based on rate
* Fix CI
* Migrate to Yunet
* Something is off here
* We indeed need semaphore for yunet
* Normalize the normed_embedding
* Fix download of models
* Fix download of models
* Fix download of models
* Add score and improve affine_matrix
* Temp fix for bbox out of frame
* Temp fix for bbox out of frame
* ROCM and OpenVINO mapping for torch backends
* Normalize bbox
* Implement gender age
* Cosmetics on cli args
* Prevent face jumping
* Fix the paste back speed
* FIx import
* Introduce detection size
* Cosmetics on face analyser ARGS and globals
* Temp fix for shaking face
* Accurate event handling
* Accurate event handling
* Accurate event handling
* Set the reference_frame_number in face_selector component
* Simswap model (#171)
* Add simswap models
* Add ghost models
* Introduce normed template
* Conditional prepare and normalize for ghost
* Conditional prepare and normalize for ghost
* Get simswap working
* Get simswap working
* Fix refresh of swapper model
* Refine face selection and detection (#174)
* Refine face selection and detection
* Update README.md
* Fix some face analyser UI
* Fix some face analyser UI
* Introduce range handling for CLI arguments
* Introduce range handling for CLI arguments
* Fix some spacings
* Disable onnxruntime warnings
* Use cv2.blur over cv2.GaussianBlur for better performance
* Revert "Use cv2.blur over cv2.GaussianBlur for better performance"
This reverts commit bab666d6f9.
* Prepare universal face detection
* Prepare universal face detection part2
* Reimplement retinaface
* Introduce cached anchors creation
* Restore filtering to enhance performance
* Minor changes
* Minor changes
* More code but easier to understand
* Minor changes
* Rename predictor to content analyser
* Change detection/recognition to detector/recognizer
* Fix crop frame borders
* Fix spacing
* Allow normalize output without a source
* Improve conditional set face reference
* Update dependencies
* Add timeout for get_download_size
* Fix performance due disorder
* Move models to assets repository, Adjust namings
* Refactor face analyser
* Rename models once again
* Fix spacing
* Highres simswap (#192)
* Introduce highres simswap
* Fix simswap 256 color issue (#191)
* Fix simswap 256 color issue
* Update face_swapper.py
* Normalize models and host in our repo
* Normalize models and host in our repo
---------
Co-authored-by: Harisreedhar <46858047+harisreedhar@users.noreply.github.com>
* Rename face analyser direction to face analyser order
* Improve the UI for face selector
* Add best-worst, worst-best detector ordering
* Clear as needed and fix zero score bug
* Fix linter
* Improve startup time by multi thread remote download size
* Just some cosmetics
* Normalize swagger source input, Add blendface_256 (unfinished)
* New paste back (#195)
* add new paste_back (#194)
* add new paste_back
* Update face_helper.py
* Update face_helper.py
* add commandline arguments and gui
* fix conflict
* Update face_mask.py
* type fix
* Clean some wording and typing
---------
Co-authored-by: Harisreedhar <46858047+harisreedhar@users.noreply.github.com>
* Clean more names, use blur range approach
* Add blur padding range
* Change the padding order
* Fix yunet filename
* Introduce face debugger
* Use percent for mask padding
* Ignore this
* Ignore this
* Simplify debugger output
* implement blendface (#198)
* Clean up after the genius
* Add gpen_bfr_256
* Cosmetics
* Ignore face_mask_padding on face enhancer
* Update face_debugger.py (#202)
* Shrink debug_face() to a minimum
* Mark as 2.0.0 release
* remove unused (#204)
* Apply NMS (#205)
* Apply NMS
* Apply NMS part2
* Fix restoreformer url
* Add debugger cli and gui components (#206)
* Add debugger cli and gui components
* update
* Polishing the types
* Fix usage in README.md
* Update onnxruntime
* Support for webp
* Rename paste-back to face-mask
* Add license to README
* Add license to README
* Extend face selector mode by one
* Update utilities.py (#212)
* Stop inline camera on stream
* Minor webcam updates
* Gracefully start and stop webcam
* Rename capture to video_capture
* Make get webcam capture pure
* Check webcam to not be None
* Remove some is not None
* Use index 0 for webcam
* Remove memory lookup within progress bar
* Less progress bar updates
* Uniform progress bar
* Use classic progress bar
* Fix image and video validation
* Use different hash for cache
* Use best-worse order for webcam
* Normalize padding like CSS
* Update preview
* Fix max memory
* Move disclaimer and license to the docs
* Update wording in README
* Add LICENSE.md
* Fix argument in README
---------
Co-authored-by: Harisreedhar <46858047+harisreedhar@users.noreply.github.com>
Co-authored-by: alex00ds <31631959+alex00ds@users.noreply.github.com>
7.6 KiB
7.6 KiB
FaceFusion
Next generation face swapper and enhancer.

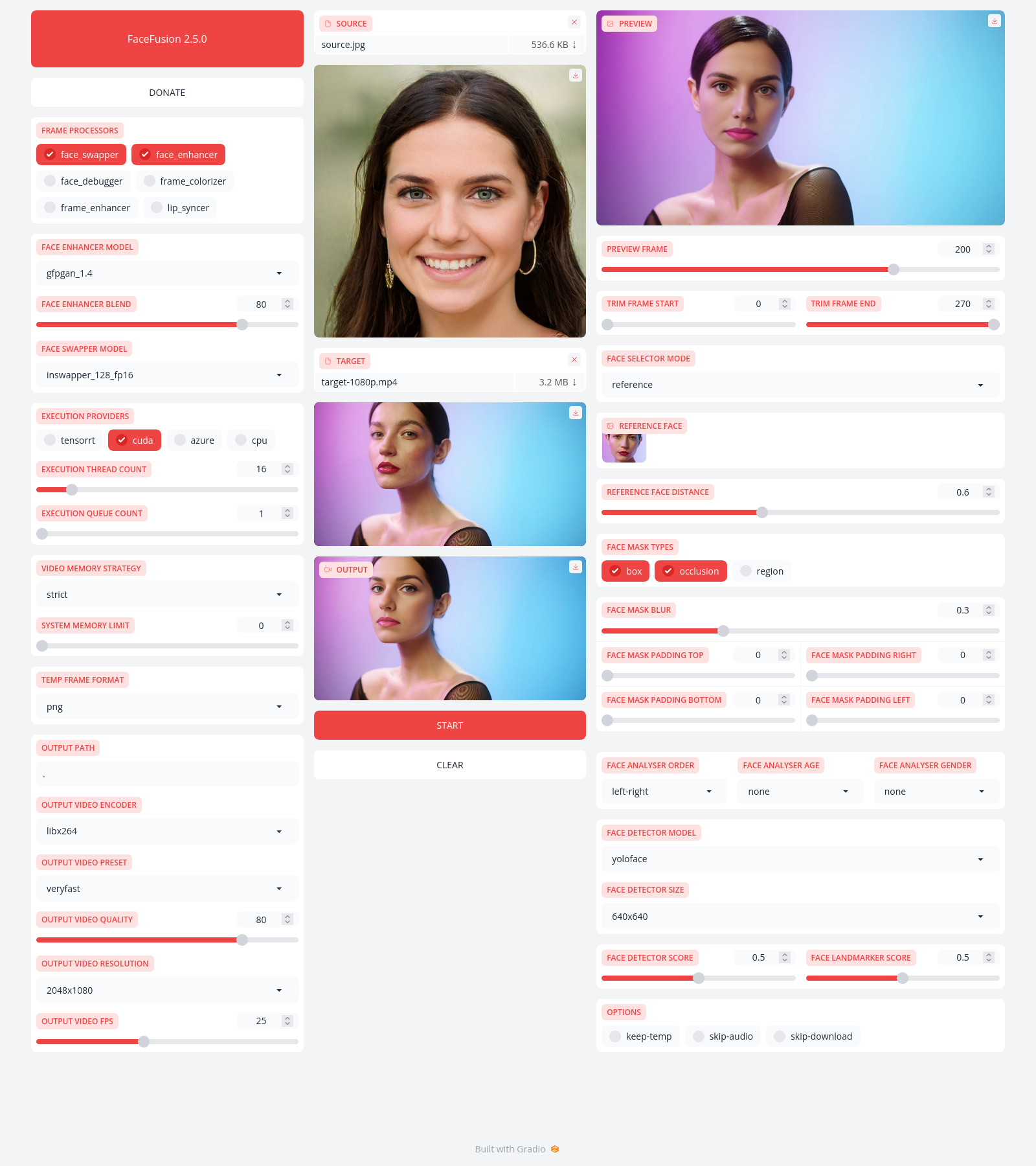
Preview
Installation
Be aware, the installation needs technical skills and is not for beginners. Please do not open platform and installation related issues on GitHub. We have a very helpful Discord community that will guide you to complete the installation.
Get started with the installation guide.
Usage
Run the command:
python run.py [options]
options:
-h, --help show this help message and exit
-s SOURCE_PATH, --source SOURCE_PATH select a source image
-t TARGET_PATH, --target TARGET_PATH select a target image or video
-o OUTPUT_PATH, --output OUTPUT_PATH specify the output file or directory
-v, --version show program's version number and exit
misc:
--skip-download omit automate downloads and lookups
--headless run the program in headless mode
execution:
--execution-providers {cpu} [{cpu} ...] choose from the available execution providers
--execution-thread-count [1-128] specify the number of execution threads
--execution-queue-count [1-32] specify the number of execution queries
--max-memory [0-128] specify the maximum amount of ram to be used (in gb)
face analyser:
--face-analyser-order {left-right,right-left,top-bottom,bottom-top,small-large,large-small,best-worst,worst-best} specify the order used for the face analyser
--face-analyser-age {child,teen,adult,senior} specify the age used for the face analyser
--face-analyser-gender {male,female} specify the gender used for the face analyser
--face-detector-model {retinaface,yunet} specify the model used for the face detector
--face-detector-size {160x160,320x320,480x480,512x512,640x640,768x768,960x960,1024x1024} specify the size threshold used for the face detector
--face-detector-score [0.0-1.0] specify the score threshold used for the face detector
face selector:
--face-selector-mode {reference,one,many} specify the mode for the face selector
--reference-face-position REFERENCE_FACE_POSITION specify the position of the reference face
--reference-face-distance [0.0-1.5] specify the distance between the reference face and the target face
--reference-frame-number REFERENCE_FRAME_NUMBER specify the number of the reference frame
face mask:
--face-mask-blur [0.0-1.0] specify the blur amount for face mask
--face-mask-padding FACE_MASK_PADDING [FACE_MASK_PADDING ...] specify the face mask padding (top, right, bottom, left) in percent
frame extraction:
--trim-frame-start TRIM_FRAME_START specify the start frame for extraction
--trim-frame-end TRIM_FRAME_END specify the end frame for extraction
--temp-frame-format {jpg,png} specify the image format used for frame extraction
--temp-frame-quality [0-100] specify the image quality used for frame extraction
--keep-temp retain temporary frames after processing
output creation:
--output-image-quality [0-100] specify the quality used for the output image
--output-video-encoder {libx264,libx265,libvpx-vp9,h264_nvenc,hevc_nvenc} specify the encoder used for the output video
--output-video-quality [0-100] specify the quality used for the output video
--keep-fps preserve the frames per second (fps) of the target
--skip-audio omit audio from the target
frame processors:
--frame-processors FRAME_PROCESSORS [FRAME_PROCESSORS ...] choose from the available frame processors (choices: face_debugger, face_enhancer, face_swapper, frame_enhancer, ...)
--face-debugger-items {bbox,kps,face-mask,score} [{bbox,kps,face-mask,score} ...] specify the face debugger items
--face-enhancer-model {codeformer,gfpgan_1.2,gfpgan_1.3,gfpgan_1.4,gpen_bfr_256,gpen_bfr_512,restoreformer} choose the model for the frame processor
--face-enhancer-blend [0-100] specify the blend factor for the frame processor
--face-swapper-model {blendface_256,inswapper_128,inswapper_128_fp16,simswap_256,simswap_512_unofficial} choose the model for the frame processor
--frame-enhancer-model {real_esrgan_x2plus,real_esrgan_x4plus,real_esrnet_x4plus} choose the model for the frame processor
--frame-enhancer-blend [0-100] specify the blend factor for the frame processor
uis:
--ui-layouts UI_LAYOUTS [UI_LAYOUTS ...] choose from the available ui layouts (choices: benchmark, webcam, default, ...)
Documentation
Read the documentation for a deep dive.