* feat/yoloface (#334)
* added yolov8 to face_detector (#323)
* added yolov8 to face_detector
* added yolov8 to face_detector
* Initial cleanup and renaming
* Update README
* refactored detect_with_yoloface (#329)
* refactored detect_with_yoloface
* apply review
* Change order again
* Restore working code
* modified code (#330)
* refactored detect_with_yoloface
* apply review
* use temp_frame in detect_with_yoloface
* reorder
* modified
* reorder models
* Tiny cleanup
---------
Co-authored-by: tamoharu <133945583+tamoharu@users.noreply.github.com>
* include audio file functions (#336)
* Add testing for audio handlers
* Change order
* Fix naming
* Use correct typing in choices
* Update help message for arguments, Notation based wording approach (#347)
* Update help message for arguments, Notation based wording approach
* Fix installer
* Audio functions (#345)
* Update ffmpeg.py
* Create audio.py
* Update ffmpeg.py
* Update audio.py
* Update audio.py
* Update typing.py
* Update ffmpeg.py
* Update audio.py
* Rename Frame to VisionFrame (#346)
* Minor tidy up
* Introduce audio testing
* Add more todo for testing
* Add more todo for testing
* Fix indent
* Enable venv on the fly
* Enable venv on the fly
* Revert venv on the fly
* Revert venv on the fly
* Force Gradio to shut up
* Force Gradio to shut up
* Clear temp before processing
* Reduce terminal output
* include audio file functions
* Enforce output resolution on merge video
* Minor cleanups
* Add age and gender to face debugger items (#353)
* Add age and gender to face debugger items
* Rename like suggested in the code review
* Fix the output framerate vs. time
* Lip Sync (#356)
* Cli implementation of wav2lip
* - create get_first_item()
- remove non gan wav2lip model
- implement video memory strategy
- implement get_reference_frame()
- implement process_image()
- rearrange crop_mask_list
- implement test_cli
* Simplify testing
* Rename to lip syncer
* Fix testing
* Fix testing
* Minor cleanup
* Cuda 12 installer (#362)
* Make cuda nightly (12) the default
* Better keep legacy cuda just in case
* Use CUDA and ROCM versions
* Remove MacOS options from installer (CoreML include in default package)
* Add lip-syncer support to source component
* Add lip-syncer support to source component
* Fix the check in the source component
* Add target image check
* Introduce more helpers to suite the lip-syncer needs
* Downgrade onnxruntime as of buggy 1.17.0 release
* Revert "Downgrade onnxruntime as of buggy 1.17.0 release"
This reverts commit f4a7ae6824.
* More testing and add todos
* Fix the frame processor API to at least not throw errors
* Introduce dict based frame processor inputs (#364)
* Introduce dict based frame processor inputs
* Forgot to adjust webcam
* create path payloads (#365)
* create index payload to paths for process_frames
* rename to payload_paths
* This code now is poetry
* Fix the terminal output
* Make lip-syncer work in the preview
* Remove face debugger test for now
* Reoder reference_faces, Fix testing
* Use inswapper_128 on buggy onnxruntime 1.17.0
* Undo inswapper_128_fp16 duo broken onnxruntime 1.17.0
* Undo inswapper_128_fp16 duo broken onnxruntime 1.17.0
* Fix lip_syncer occluder & region mask issue
* Fix preview once in case there was no output video fps
* fix lip_syncer custom fps
* remove unused import
* Add 68 landmark functions (#367)
* Add 68 landmark model
* Add landmark to face object
* Re-arrange and modify typing
* Rename function
* Rearrange
* Rearrange
* ignore type
* ignore type
* change type
* ignore
* name
* Some cleanup
* Some cleanup
* Opps, I broke something
* Feat/face analyser refactoring (#369)
* Restructure face analyser and start TDD
* YoloFace and Yunet testing are passing
* Remove offset from yoloface detection
* Cleanup code
* Tiny fix
* Fix get_many_faces()
* Tiny fix (again)
* Use 320x320 fallback for retinaface
* Fix merging mashup
* Upload wave2lip model
* Upload 2dfan2 model and rename internal to face_predictor
* Downgrade onnxruntime for most cases
* Update for the face debugger to render landmark 68
* Try to make detect_face_landmark_68() and detect_gender_age() more uniform
* Enable retinaface testing for 320x320
* Make detect_face_landmark_68() and detect_gender_age() as uniform as … (#370)
* Make detect_face_landmark_68() and detect_gender_age() as uniform as possible
* Revert landmark scale and translation
* Make box-mask for lip-syncer adjustable
* Add create_bbox_from_landmark()
* Remove currently unused code
* Feat/uniface (#375)
* add uniface (#373)
* Finalize UniFace implementation
---------
Co-authored-by: Harisreedhar <46858047+harisreedhar@users.noreply.github.com>
* My approach how todo it
* edit
* edit
* replace vertical blur with gaussian
* remove region mask
* Rebase against next and restore method
* Minor improvements
* Minor improvements
* rename & add forehead padding
* Adjust and host uniface model
* Use 2dfan4 model
* Rename to face landmarker
* Feat/replace bbox with bounding box (#380)
* Add landmark 68 to 5 convertion
* Add landmark 68 to 5 convertion
* Keep 5, 5/68 and 68 landmarks
* Replace kps with landmark
* Replace bbox with bounding box
* Reshape face_landmark5_list different
* Make yoloface the default
* Move convert_face_landmark_68_to_5 to face_helper
* Minor spacing issue
* Dynamic detector sizes according to model (#382)
* Dynamic detector sizes according to model
* Dynamic detector sizes according to model
* Undo false commited files
* Add lib syncer model to the UI
* fix halo (#383)
* Bump to 2.3.0
* Update README and wording
* Update README and wording
* Fix spacing
* Apply _vision suffix
* Apply _vision suffix
* Apply _vision suffix
* Apply _vision suffix
* Apply _vision suffix
* Apply _vision suffix
* Apply _vision suffix, Move mouth mask to face_masker.py
* Apply _vision suffix
* Apply _vision suffix
* increase forehead padding
---------
Co-authored-by: tamoharu <133945583+tamoharu@users.noreply.github.com>
Co-authored-by: Harisreedhar <46858047+harisreedhar@users.noreply.github.com>
108 lines
9.5 KiB
Markdown
108 lines
9.5 KiB
Markdown
FaceFusion
|
|
==========
|
|
|
|
> Next generation face swapper and enhancer.
|
|
|
|
[](https://github.com/facefusion/facefusion/actions?query=workflow:ci)
|
|

|
|
|
|
|
|
Preview
|
|
-------
|
|
|
|
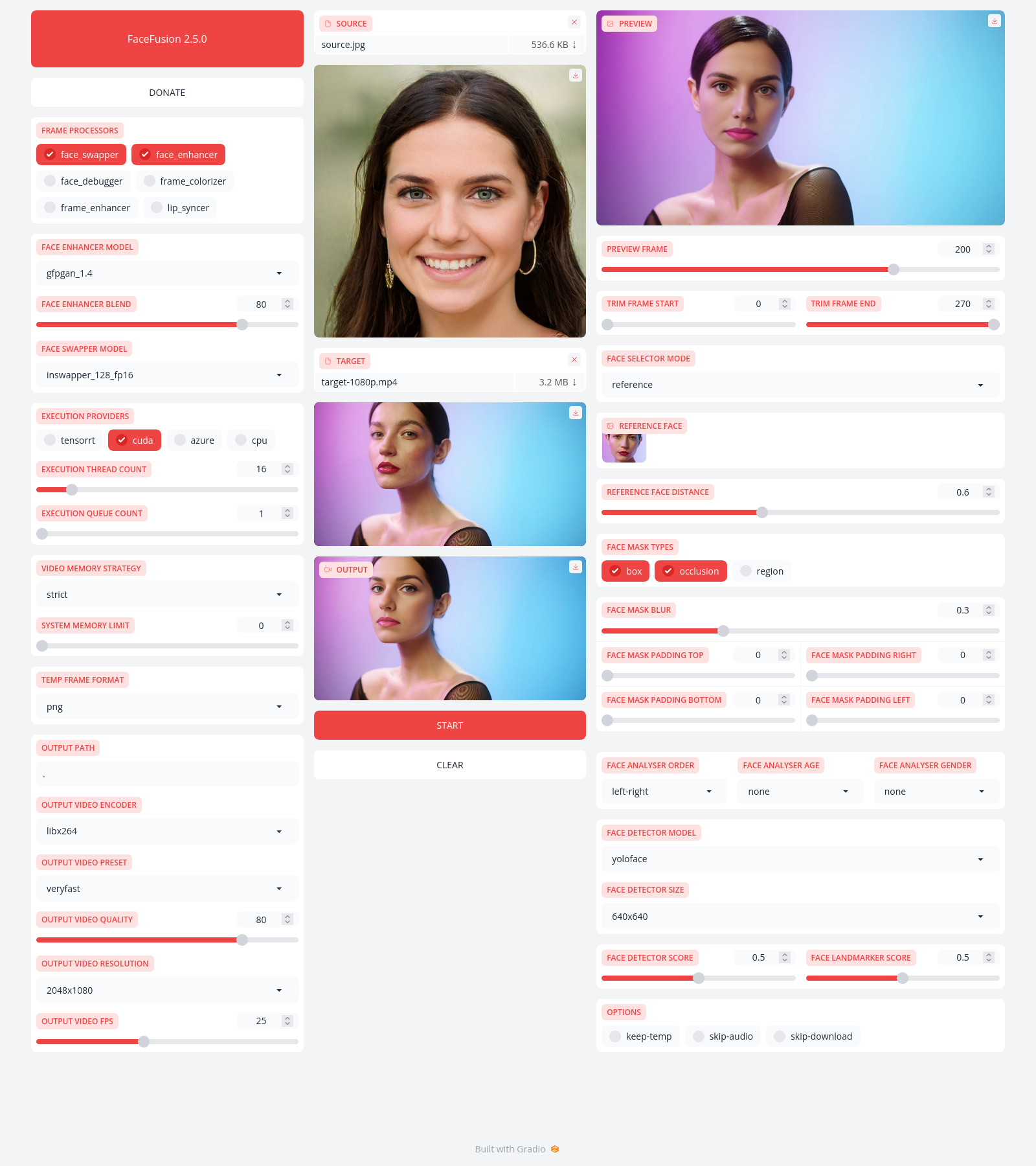
|
|
|
|
|
|
Installation
|
|
------------
|
|
|
|
Be aware, the installation needs technical skills and is not for beginners. Please do not open platform and installation related issues on GitHub. We have a very helpful [Discord](https://join.facefusion.io) community that will guide you to complete the installation.
|
|
|
|
Get started with the [installation](https://docs.facefusion.io/installation) guide.
|
|
|
|
|
|
Usage
|
|
-----
|
|
|
|
Run the command:
|
|
|
|
```
|
|
python run.py [options]
|
|
|
|
options:
|
|
-h, --help show this help message and exit
|
|
-s SOURCE_PATHS, --source SOURCE_PATHS choose single or multiple source images
|
|
-t TARGET_PATH, --target TARGET_PATH choose single target image or video
|
|
-o OUTPUT_PATH, --output OUTPUT_PATH specify the output file or directory
|
|
-v, --version show program's version number and exit
|
|
|
|
misc:
|
|
--skip-download omit automate downloads and remote lookups
|
|
--headless run the program without a user interface
|
|
--log-level {error,warn,info,debug} adjust the message severity displayed in the terminal
|
|
|
|
execution:
|
|
--execution-providers EXECUTION_PROVIDERS [EXECUTION_PROVIDERS ...] accelerate the model inference using different providers (choices: cpu, ...)
|
|
--execution-thread-count [1-128] specify the amount of parallel threads while processing
|
|
--execution-queue-count [1-32] specify the amount of frames each thread is processing
|
|
|
|
memory:
|
|
--video-memory-strategy {strict,moderate,tolerant} balance fast frame processing and low vram usage
|
|
--system-memory-limit [0-128] limit the available ram that can be used while processing
|
|
|
|
face analyser:
|
|
--face-analyser-order {left-right,right-left,top-bottom,bottom-top,small-large,large-small,best-worst,worst-best} specify the order in which the face analyser detects faces.
|
|
--face-analyser-age {child,teen,adult,senior} filter the detected faces based on their age
|
|
--face-analyser-gender {female,male} filter the detected faces based on their gender
|
|
--face-detector-model {retinaface,yoloface,yunet} choose the model responsible for detecting the face
|
|
--face-detector-size FACE_DETECTOR_SIZE specify the size of the frame provided to the face detector
|
|
--face-detector-score [0.0-1.0] filter the detected faces base on the confidence score
|
|
|
|
face selector:
|
|
--face-selector-mode {reference,one,many} use reference based tracking with simple matching
|
|
--reference-face-position REFERENCE_FACE_POSITION specify the position used to create the reference face
|
|
--reference-face-distance [0.0-1.5] specify the desired similarity between the reference face and target face
|
|
--reference-frame-number REFERENCE_FRAME_NUMBER specify the frame used to create the reference face
|
|
|
|
face mask:
|
|
--face-mask-types FACE_MASK_TYPES [FACE_MASK_TYPES ...] mix and match different face mask types (choices: box, occlusion, region)
|
|
--face-mask-blur [0.0-1.0] specify the degree of blur applied the box mask
|
|
--face-mask-padding FACE_MASK_PADDING [FACE_MASK_PADDING ...] apply top, right, bottom and left padding to the box mask
|
|
--face-mask-regions FACE_MASK_REGIONS [FACE_MASK_REGIONS ...] choose the facial features used for the region mask (choices: skin, left-eyebrow, right-eyebrow, left-eye, right-eye, eye-glasses, nose, mouth, upper-lip, lower-lip)
|
|
|
|
frame extraction:
|
|
--trim-frame-start TRIM_FRAME_START specify the the start frame of the target video
|
|
--trim-frame-end TRIM_FRAME_END specify the the end frame of the target video
|
|
--temp-frame-format {bmp,jpg,png} specify the temporary resources format
|
|
--temp-frame-quality [0-100] specify the temporary resources quality
|
|
--keep-temp keep the temporary resources after processing
|
|
|
|
output creation:
|
|
--output-image-quality [0-100] specify the image quality which translates to the compression factor
|
|
--output-video-encoder {libx264,libx265,libvpx-vp9,h264_nvenc,hevc_nvenc} specify the encoder use for the video compression
|
|
--output-video-preset {ultrafast,superfast,veryfast,faster,fast,medium,slow,slower,veryslow} balance fast video processing and video file size
|
|
--output-video-quality [0-100] specify the video quality which translates to the compression factor
|
|
--output-video-resolution OUTPUT_VIDEO_RESOLUTION specify the video output resolution based on the target video
|
|
--output-video-fps OUTPUT_VIDEO_FPS specify the video output fps based on the target video
|
|
--skip-audio omit the audio from the target video
|
|
|
|
frame processors:
|
|
--frame-processors FRAME_PROCESSORS [FRAME_PROCESSORS ...] load a single or multiple frame processors. (choices: face_debugger, face_enhancer, face_swapper, frame_enhancer, lip_syncer, ...)
|
|
--face-debugger-items FACE_DEBUGGER_ITEMS [FACE_DEBUGGER_ITEMS ...] load a single or multiple frame processors (choices: bounding-box, landmark-5, landmark-68, face-mask, score, age, gender)
|
|
--face-enhancer-model {codeformer,gfpgan_1.2,gfpgan_1.3,gfpgan_1.4,gpen_bfr_256,gpen_bfr_512,restoreformer_plus_plus} choose the model responsible for enhancing the face
|
|
--face-enhancer-blend [0-100] blend the enhanced into the previous face
|
|
--face-swapper-model {blendswap_256,inswapper_128,inswapper_128_fp16,simswap_256,simswap_512_unofficial,uniface_256} choose the model responsible for swapping the face
|
|
--frame-enhancer-model {real_esrgan_x2plus,real_esrgan_x4plus,real_esrnet_x4plus} choose the model responsible for enhancing the frame
|
|
--frame-enhancer-blend [0-100] blend the enhanced into the previous frame
|
|
--lip-syncer-model {wav2lip_gan} choose the model responsible for syncing the lips
|
|
|
|
uis:
|
|
--ui-layouts UI_LAYOUTS [UI_LAYOUTS ...] launch a single or multiple UI layouts (choices: benchmark, default, webcam, ...)
|
|
```
|
|
|
|
|
|
Documentation
|
|
-------------
|
|
|
|
Read the [documentation](https://docs.facefusion.io) for a deep dive.
|